
Developing Autonomous Drone Swarms with Multi-Agent Reinforcement Learning for Scalable Post-Disaster Damage Assessment
2021 CUSP Capstone Project - NYU
PROBLEM STATEMENT
Damage assessment of buildings, roads, and infrastructure is a key post-disaster activity. Drones have been used in actual damage assessment activities for past years, however, scalability is still underdeveloped. This research project applies Multi-Agent Q-learning to autonomous navigation for mapping and multi-objective drone swarm exploration of a disaster area in terms of tradeoffs between coverage and scalability. Also, we empirically specify parametric thresholds for the performance of a multi-objective RL algorithm as a point of reference for future work incorporating deep learning approaches, e.g., Graph Neural Networks (GNNs).

METHODOLOGY
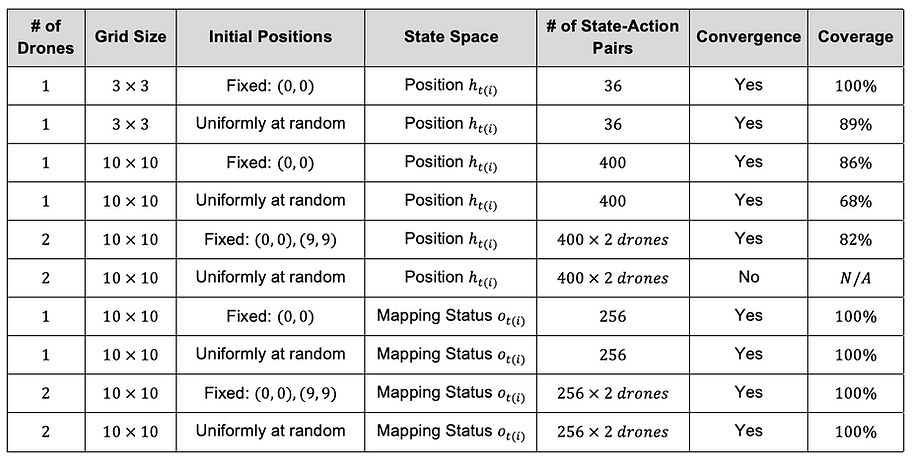
We discretize the 2-dimensional mission environment (disaster area) into a grid consisting of 𝑚 × 𝑚 square cells. The cell visited by at least one drone is considered mapped. We iterate episodes 500 times for the 3 × 3 grid and 200,000 times for the 10 × 10 grid to train drones. The maximum time steps for each episode are twice the number of cells.

01
Multi-Agent Q-learning
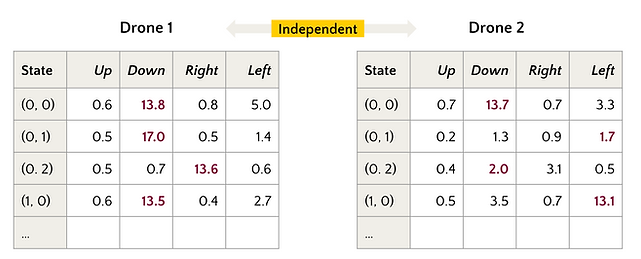
We use Q-learning to define the baseline performance of the mapping task. In a multi-drone scenario, each drone has an independent action-value function 𝑄 as a table and takes action without explicitly sharing its state with each other.
02
Sequential Decision-Making
Each time step, 𝑛 drones take action sequentially; the preceding drone mapping results are reflected in the status matrix 𝑀 before the following one decides its action. Therefore, the following drone could indirectly and partially observe the preceding ones’ behaviors. The order of drones taking action is randomly set in each time step.

03
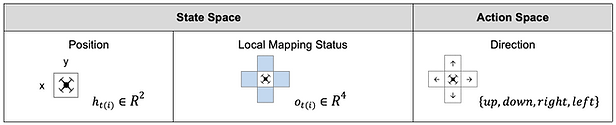
State and Action Space
We examine two state spaces to deal with possible disaster areas and scenarios. First, we directly use drones’ location as a state. In another one, we use drones’ observations within their Field of View (FOV) as a state. Action space consists of four possible directions, 𝐴 = {𝑢𝑝, 𝑑𝑜𝑤𝑛, 𝑟𝑖𝑔h𝑡, 𝑙𝑒𝑓𝑡}. In each time step, drones can choose the direction and move by one cell, except that actions that would take drones off the environment leave the position unchanged.
RESULTS
01
Convergence
First, we verified convergence to the optimal action-value function 𝑞∗ in each simulation to see if our setting works in the RL framework. After convergence is achieved, greedy actions with respect to the maximum of the action-value in all states should be stationary. We confirmed such convergence except for the 2-drone simulation with random initial positions and the positions as a state. It is because the randomness of initial positions made it difficult for a drone to estimate another one's policy, and the mapping status of the visited cell’s neighbors was not always the same.
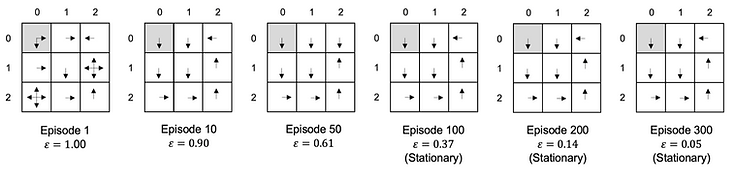
Example of convergence: 1-drone greedy policy using a drone’s position as a state in 3 x 3 grid, trained with the fixed initial position
02
Coverage
Next, we compared coverage of the grid when we followed each simulation’s greedy policy after convergence to measure how good each algorithm was. We observed that the coverages of using the local mapping status as a state outperformed the positions regardless of the number of drones and their initial positions in the training. This result could come from the direct relationship between state and immediate reward; drones can predict the immediate reward of each action by directly observing the mapping status. Thus, greedy policies were less prone to converge to local optima.


Position as a state: 2-drone greedy policies in 10 x 10 grid, trained with the fixed initial position

Observation (mapping status) as a state: trajectory of the 2-drone greedy policies in 10 x 10 grid,
trained with the fixed initial positions
03
Scalability
In addition to coverage, we confirmed that another benefit of using the local mapping status as a state is scalability. Its complexity, the number of state-action pairs, with regards to the size of the grid 𝑚 is constant, 𝑂(1). Thus, we can train the algorithms in smaller grids and deploy them to larger grids. On the other hand, the complexity of the algorithms using positions as a state is 𝑂(𝑚**2) and they need separate training when the grid size is different.


Observation (mapping status) as a state: trajectory of the 1-drone greedy policy,
trained with the fixed initial position
04
Challenges
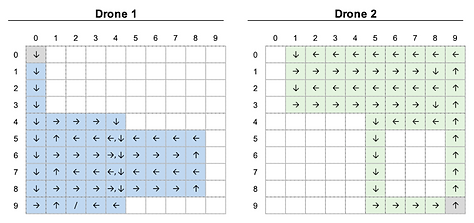
The challenge of the algorithms using the local mapping status as a state was the chance that a drone would take redundant actions. The below figure shows the trajectories starting from (0, 0) and (9, 9) when we followed the 2- drone simulation’s greedy policy trained with random initial positions. Although the coverage got to 100%, drone 2 ended up with the infinite loop between (9,0) and (9,1), which was a redundant behavior. Thus, the contribution of drones was skewed and the time steps to complete mapping was far from the minimum. The redundancy could increase in proportion to the number of drones used as long as they are independent, which means that the scalability is limited.

Observation (mapping status) as a state: trajectory of the 2-drone greedy policies in 10 x 10 grid,
trained with random initial positions
More examples of redundant actions are shown below.
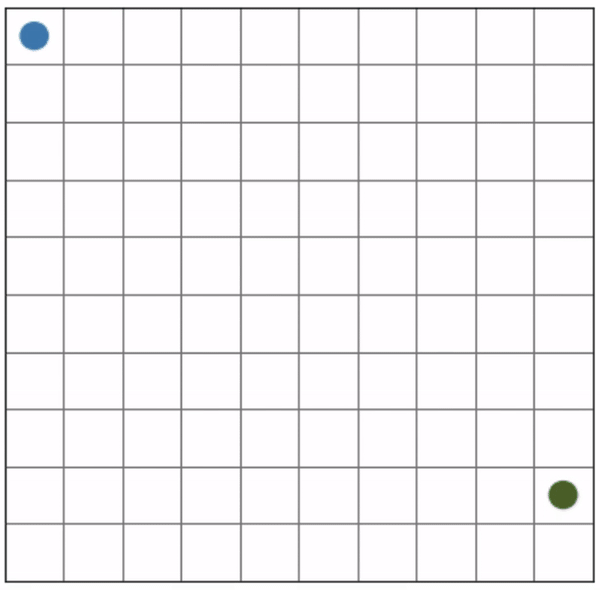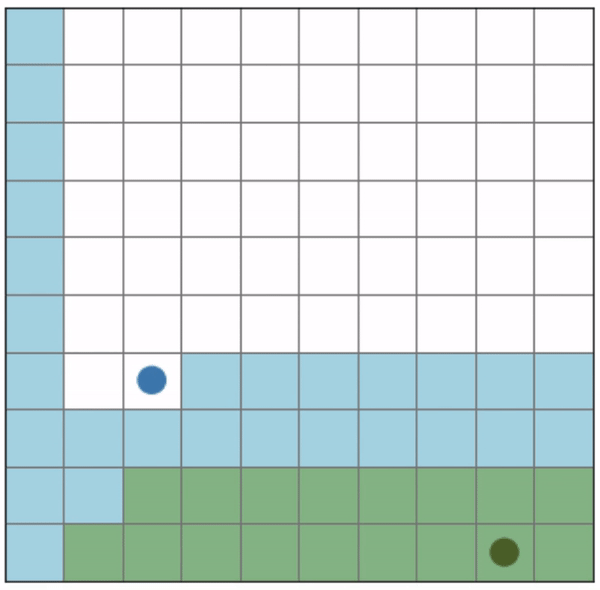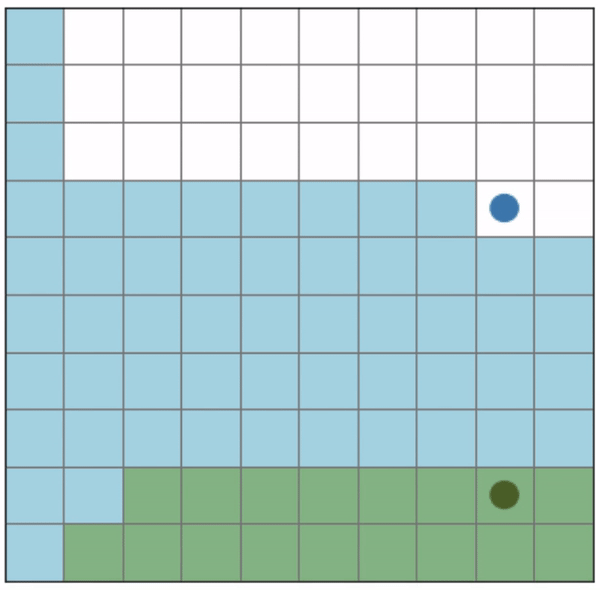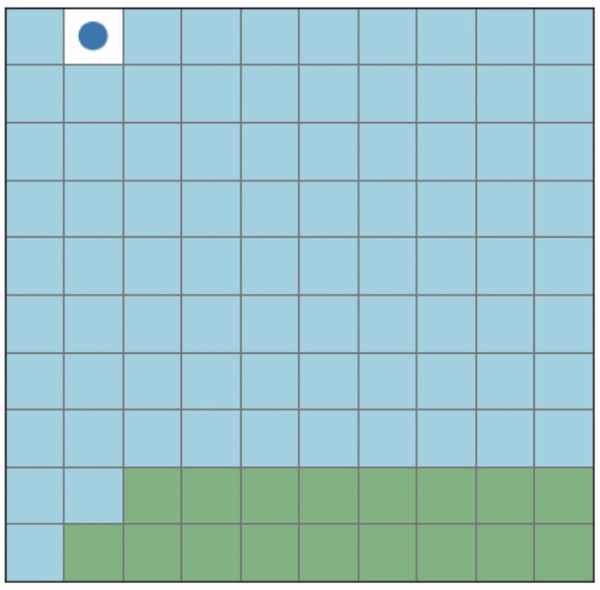
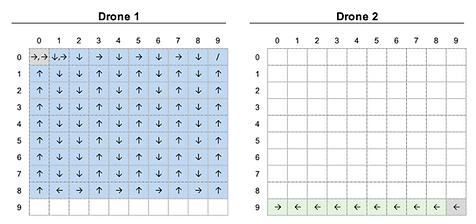
Initial positions: (0, 0), (8, 9)

Initial positions: (0, 9), (0, 0)
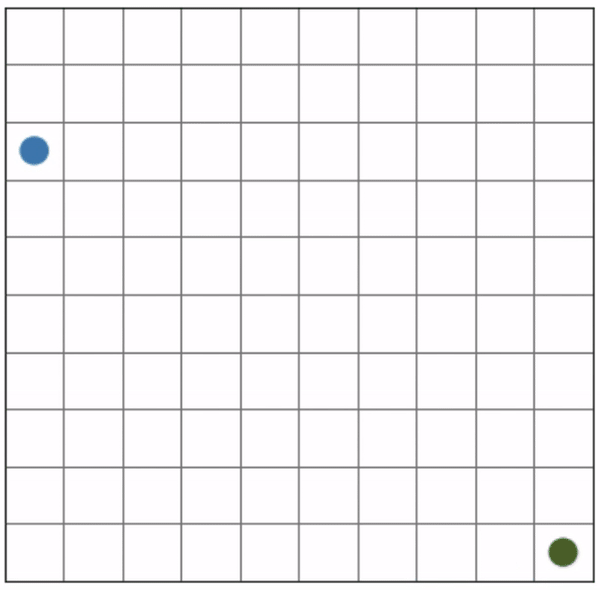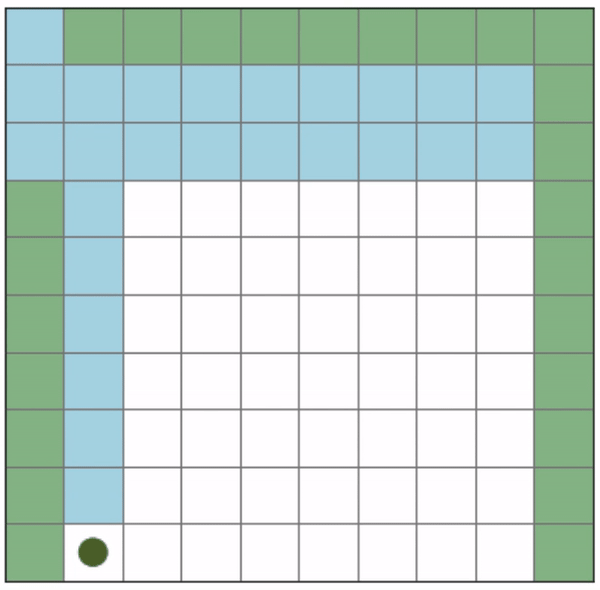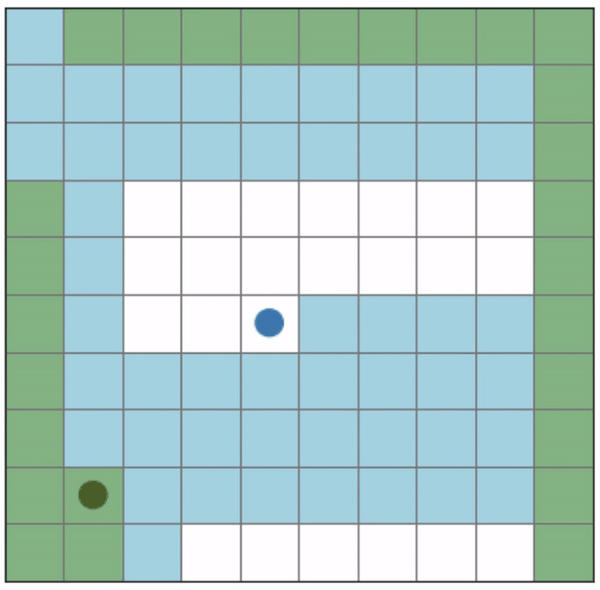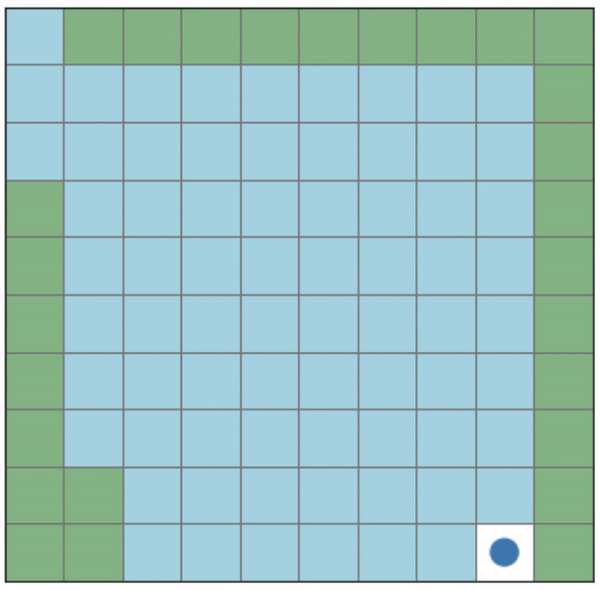
Initial positions: (2, 0), (9, 9)
CONCLUSION
In this research, we modeled the deployment of autonomous drone swarms to post-disaster damage assessment as the mapping task. We compared two different state spaces and found that using drones’ observations of the mapping status within their FOV as a state is a better solution in terms of coverage and scalability. This result implies that we can develop a decentralized control version; each drone takes action only consuming a local observation without communicating with a central controller. In damage assessment, a decentralized control has two advantages. First, a centralized control system is challenging to scale up to a large number of drones because of its fragility to a single point of failures and communication outages. Second, drones can regulate themselves without Global Positioning System (GPS). In such cases where buildings surround the disaster area (e.g., downtown) or we need to inspect indoors (e.g., subway stations), a GPS signal from satellites may become too weak for drones to navigate the environment accurately. Therefore, the decentralized control using drones’ local observation as a state is a promising solution for scalable damage assessment.
We observed that the Multi-Agent Independent Q-learning had the limitation to reduce redundant actions. In damage assessment, redundancy may contribute to increasing the confidence of damage information in a particular spot. However, especially for a primary damage assessment immediately after a disaster, speed to map a disaster area thoroughly is critical. We hypothesize that incorporating GNNs as an RL policy network could minimize redundancy and achieve decentralized control. We can evaluate its performance by how efficiently the drones map the environment (e.g., time steps to reach 95% coverage). The performance of our Multi-Agent Independent Q-learning algorithm will be a baseline for such future work. Also, we assume Deep Q-Networks could be another baseline.
DEMO
